
Rolldown-Vite 实践体验:基于 Rust 的新一代构建工具
前言
作为一名长期使用 Vite 进行前端开发的工程师,当看到官方发布 rolldown-vite 的消息时,我对这个基于 Rust 的新构建工具产生了浓厚的兴趣。
本文将记录我在实际项目中使用 rolldown-vite 的体验过程,包括迁移步骤、性能对比、新特性分析以及使用建议。
Rolldown 概述
技术背景
Rolldown 是一个用 Rust 编写的现代化 JavaScript 打包工具,定位为 Rollup 的高性能替代方案。在当前前端工具链普遍向 Rust 迁移的趋势下(如 swc、esbuild、turbo),Vite 团队也选择了这条技术路线。
Rolldown 的核心目标是在保持与现有生态系统完全兼容的前提下,通过 Rust 的性能优势实现显著的构建速度提升。
架构优势分析
相比传统方案,Rolldown 带来了三个主要改进:
1. 工具链统一
传统 Vite 架构存在二元化问题:
- 开发环境:esbuild 负责依赖预打包
- 生产环境:Rollup 负责最终构建
这种架构分离偶尔会导致开发与生产环境的行为不一致。Rolldown 通过统一的构建引擎解决了这一问题。
2. 性能优化
Rust 的系统级性能优势在 I/O 密集型的构建任务中表现尤为明显。虽然具体提升程度因项目规模而异,但理论上应该有显著的性能收益。
迁移实践
迁移流程
迁移过程相对简单,主要通过 npm 别名机制实现:
{
"dependencies": {
"vite": "npm:rolldown-vite@latest"
}
}
完成依赖更新后,重新执行 npm install 即可。需要注意的是,首次安装可能需要较长时间,建议使用稳定的网络环境或配置国内镜像源。
性能测试结果
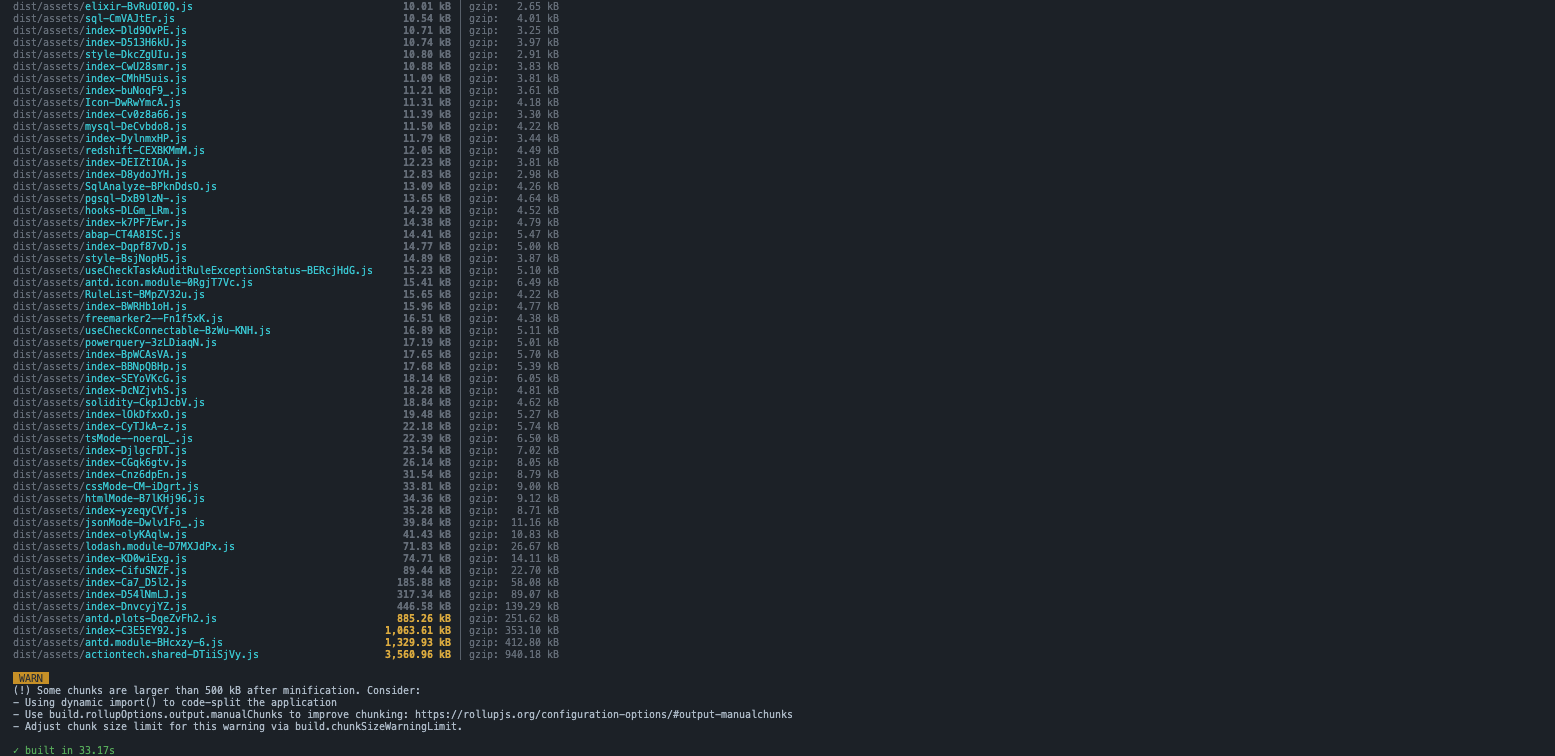
我在一个包含约 200+ 组件的中型 React 项目上进行了构建性能对比:
原版 Vite 构建时间:
Rolldown-Vite 构建时间:
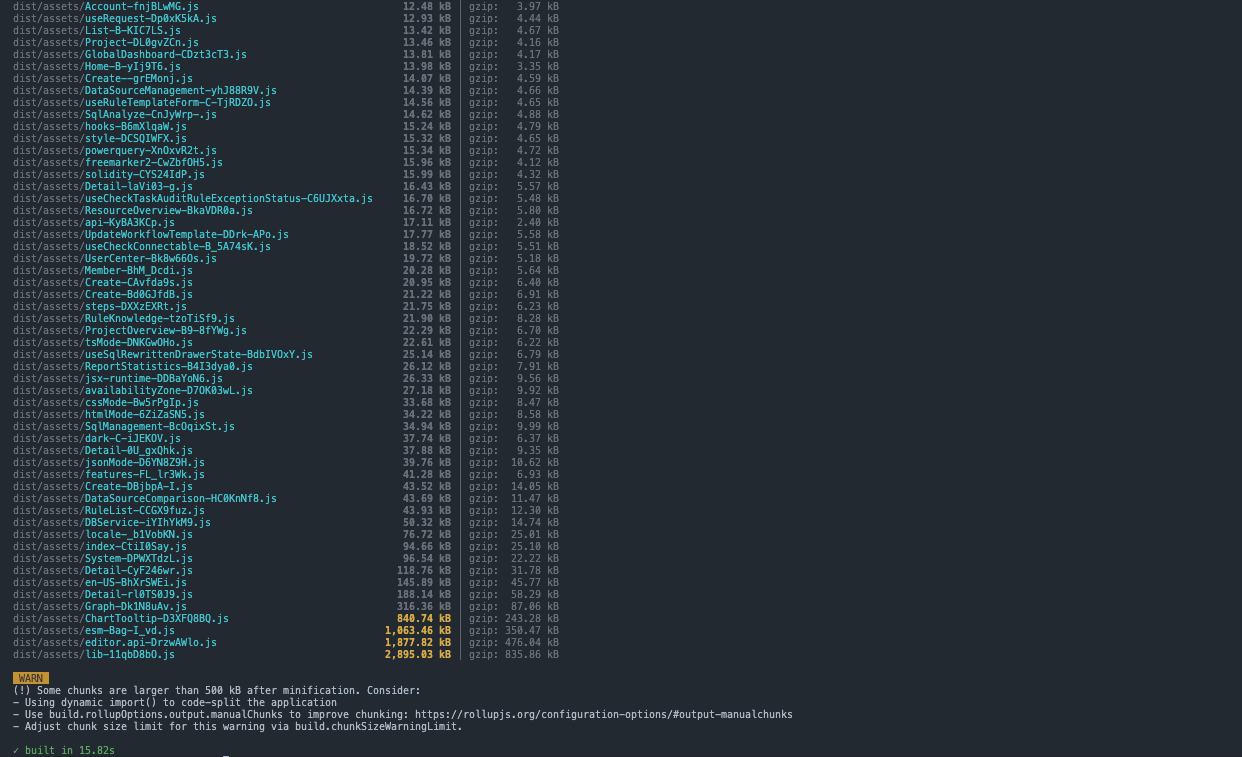
从测试结果来看,在构建项目产物场景下确实能观察到性能提升。
核心特性变化
分块策略调整
Rolldown 最显著的变化是将 manualChunks 替换为 advancedChunks,这是一个更具表达力的分块配置系统:
// 传统 Rollup 配置
export default {
build: {
rollupOptions: {
output: {
manualChunks(id) {
if (/\/react(?:-dom)?/.test(id)) {
return 'vendor'
}
}
}
}
}
}
// Rolldown 新配置
export default {
build: {
rollupOptions: {
output: {
advancedChunks: {
groups: [{ name: 'vendor', test: /\/react(?:-dom)?/ }]
}
}
}
}
}
advancedChunks 的行为模式更接近 webpack 的 splitChunks,提供了更精细的分块控制能力。
Runtime Chunk 机制
使用 advancedChunks 后,构建产物会自动生成一个 rolldown-runtime-{hash} 文件。这个看似简单的变化,实际上解决了传统 Rollup manualChunks 配置中的一个重要痛点。
传统 manualChunks 的依赖问题
在使用 Rollup 的 manualChunks 功能时,我们经常会遇到这样的配置:
// 典型的 manualChunks 配置
export default {
build: {
rollupOptions: {
output: {
manualChunks: {
'vendor': ['react', 'react-dom'],
'utils': ['lodash', 'axios'],
'ui': ['antd', '@ant-design/icons']
}
}
}
}
}
这种配置在大多数情况下工作正常,但在复杂项目中容易产生以下问题:
1. 循环依赖导致的加载顺序问题
假设我们有这样的模块依赖关系:
// moduleA.js
import { utilB } from './moduleB.js'
import { thirdPartyLib } from 'some-lib'
export const utilA = () => {
return utilB() + thirdPartyLib()
}
// moduleB.js
import { utilA } from './moduleA.js'
import { anotherLib } from 'another-lib'
export const utilB = () => {
// 在某些条件下可能会调用 utilA
return someCondition ? utilA() : anotherLib()
}
当 manualChunks 将这些模块分配到不同的 chunk 时,可能会产生这样的输出:
// chunk-vendor.js (包含 some-lib, another-lib)
// chunk-utils.js (包含 moduleA, moduleB)
// main.js (应用入口)
2. 运行时错误的具体表现
在实际项目中,我曾遇到过这样的错误:
Uncaught ReferenceError: Cannot access 'utilA' before initialization
或者更隐蔽的问题:
Uncaught TypeError: utilB is not a function
这类错误通常只在生产环境出现,因为开发环境使用的是非打包模式,模块加载顺序由浏览器的 ES Module 机制保证。
3. 问题的根本原因
问题的核心在于:当模块被分割到不同的 chunk 后,模块的初始化顺序变得不可预测。Rollup 在生成 chunk 时,可能会将循环依赖的模块放在不同的文件中,导致:
- Chunk A 需要 Chunk B 中的模块
- Chunk B 也需要 Chunk A 中的模块
- 但运行时加载顺序无法保证正确的初始化序列
Rolldown 的 Runtime Chunk 解决方案
Rolldown 通过强制生成 runtime.js 文件来解决这个问题:
1. 运行时代码提取
runtime.js 包含了所有必要的运行时帮助函数和模块加载逻辑:
// runtime.js (简化示例)
var __esm = (fn, module) => {
return () => {
if (!module.init) {
module.exports = {};
module.init = true;
fn.call(module.exports, module, module.exports);
}
return module.exports;
};
};
var __export = (target, all) => {
for (var name in all)
target[name] = all[name];
};
// 模块注册表
var __modules = {};
var __register = (id, fn) => {
__modules[id] = { fn, exports: {}, init: false };
};
2. 确定的加载顺序
所有其他 chunk 都会依赖 runtime.js,确保运行时代码始终最先执行:
<!-- HTML 中的加载顺序 -->
<script src="/assets/runtime-abc123.js"></script>
<script src="/assets/vendor-def456.js"></script>
<script src="/assets/main-ghi789.js"></script>
3. 安全的模块初始化
通过运行时的模块管理机制,即使存在循环依赖,也能保证安全的初始化:
// 在 runtime 管理下的模块加载
var init_moduleA = __esm({
"moduleA.js"() {
// 延迟初始化,避免循环依赖问题
var moduleB = __require("moduleB.js");
exports.utilA = () => {
return moduleB.utilB() + thirdPartyLib();
};
}
});
权衡考虑
当然,runtime.js 也带来了一些权衡:
优势:
- 彻底解决循环依赖问题
- 提高大型项目的运行时稳定性
- 为模块联邦等高级功能奠定基础
成本:
- 增加一个额外的 HTTP 请求
- 轻微增加总的 bundle 大小(通常 < 5KB)
- 需要调整构建流水线以适应新的文件结构
从我的实际使用体验来看,这个权衡是值得的。相比于在生产环境中调试循环依赖问题的复杂性,多一个 runtime 文件的成本几乎可以忽略不计。
插件生态适配
React 插件优化
对于 React 项目,官方推荐使用 @vitejs/plugin-react-oxc 替代传统的 React 插件:
- 技术基础:基于 Oxc(Rust 编写的前端工具链)
- 性能优势:与 rolldown-vite 的 Rust 架构更好匹配
- 限制条件:不支持自定义 Babel 或 SWC 插件
这个限制对于依赖复杂 Babel 配置的项目可能是个障碍,需要权衡性能收益与功能需求。
钩子过滤机制
Rolldown 引入了插件钩子过滤功能,这是一个重要的性能优化特性,解决了 Rust 打包器中跨语言调用的性能瓶颈问题。
传统插件钩子的性能问题
在传统的 Rollup 插件中,我们经常看到这样的模式:
// 典型的 Rollup 插件写法
export default function stylePlugin() {
return {
name: 'style-processor',
transform(code, id) {
// 每个模块都会触发这个钩子
if (!id.endsWith('.css') && !id.endsWith('.scss')) {
return null // 大部分情况下都是早期返回
}
// 实际的样式处理逻辑
return processStyles(code, id)
},
load(id) {
if (!id.includes('?inline')) {
return null // 又是一次无效调用
}
return inlineStyleLoader(id)
}
}
}
这种设计在 JavaScript 打包器中工作良好,但在 Rust 打包器中存在严重的性能问题:
1. 频繁的跨语言调用开销
在一个包含 1000+ 模块的项目中:
- 每个模块都会触发
transform钩子 - 大部分调用最终都是无效的(早期返回)
- Rust 到 JS 的调用本身就有开销
- 累积起来成为显著的性能瓶颈
2. 破坏 Rust 的并行优化
由于 JavaScript 的单线程特性:
- 即使 Rust 端可以并行处理多个模块
- 但插件调用必须串行化到 JS 主线程
- 降低了整体的并行处理效率
Rolldown 的过滤器设计
Rolldown 通过在插件钩子中引入 filter 属性来解决这个问题:
export default function stylePlugin() {
return {
name: 'style-processor',
transform: {
// 在 Rust 层面进行预过滤
filter: {
id: {
include: [/\.css$/, /\.scss$/],
exclude: /\.module\./
}
},
handler(code, id) {
// 只有通过过滤器的模块才会到达这里
return processStyles(code, id)
}
},
load: {
filter: {
id: /\?inline$/
},
handler(id) {
return inlineStyleLoader(id)
}
}
}
}
过滤器的详细配置
过滤器支持多种匹配条件:
{
transform: {
filter: {
// 基于文件 ID 过滤
id: {
include: [/\.ts$/, /\.tsx$/],
exclude: [/\.d\.ts$/, /node_modules/]
},
// 基于模块类型过滤
moduleType: 'js',
// 基于源代码内容过滤
code: {
include: ['export default', 'export const'],
exclude: ['// @skip-transform']
}
},
handler(code, id) {
return transformTypeScript(code, id)
}
}
}
过滤逻辑:
include数组中任意一个匹配即可通过exclude优先级高于include- 多个过滤属性之间是 AND 关系(必须全部匹配)
全量打包模式探索
全量打包模式是 rolldown-vite 的一个实验性功能,代表了对传统 Vite 开发模式的重要反思和创新尝试。
传统 Vite 开发模式的挑战
Vite 的核心竞争力源于其非打包开发服务器,这种设计在早期带来了显著的性能优势:
// 传统开发模式:每个模块独立请求
// /src/App.tsx -> http://localhost:3000/src/App.tsx
// /src/components/Header.tsx -> http://localhost:3000/src/components/Header.tsx
// /src/utils/api.ts -> http://localhost:3000/src/utils/api.ts
然而,随着项目规模增长,这种模式逐渐暴露出两个核心问题:
1. 开发与生产环境的行为差异
我在实际项目中遇到过这样的问题:
// 开发环境正常运行的代码
import { debounce } from 'lodash'
import utils from './utils' // 这里存在循环依赖
export default function SearchComponent() {
const debouncedSearch = debounce(utils.search, 300)
// ...
}
- 开发环境:浏览器的原生 ES Module 机制处理模块加载,循环依赖被自然解决
- 生产环境:Rollup 打包后,模块的初始化顺序发生变化,导致运行时错误
2. 网络性能衰减问题
在一个包含 300+ 组件的大型项目中,初始页面加载可能触发:
# Chrome DevTools Network 面板中的典型场景
200+ HTTP requests (modules)
150+ HTTP requests (dependencies)
50+ HTTP requests (assets)
---
Total: 400+ requests during development
这带来了几个实际问题:
- 开发服务器启动延迟:大量模块的按需编译
- 页面刷新缓慢:特别是在网络代理环境下
- 调试困难:网络面板中充斥着大量的模块请求
全量打包模式的设计理念
rolldown-vite 的全量打包模式试图在保持开发性能的同时解决上述问题:
// 全量打包模式的工作流程
1. 启动时进行快速的全量打包 (基于 Rust 的高性能)
2. 生成统一的 bundle,但保持模块边界清晰
3. HMR 仍然基于模块级别进行精确更新
4. 开发与生产环境使用相同的模块加载机制
结语
rolldown-vite 作为 Vite 生态的重要演进,展现了前端构建工具向 Rust 生态迁移的技术趋势。通过实际体验,可以感受到其在性能优化、开发一致性等方面的改进。新的分块机制、钩子过滤、以及实验性的全量打包模式,都体现了对传统构建工具痛点的深度思考和创新尝试。
评论区
加载评论中...